


一家陆奇、高通、英伟达都看好的公司,融资了
 AI时代真正的创业瓶颈并不是“算力”,而是“训练数据”。
AI时代真正的创业瓶颈并不是“算力”,而是“训练数据”。
在风险投资圈里,有个经典的投资人提问叫做“护城河”。
这个词是巴菲特带火的。老爷子说,那些带来丰厚投资回报的企业,普遍都拥有足够宽、足够深的护城河,确保了竞争对手无法在短期内抢走他们的业务,也让对手与他们的竞争变成了一场非常不划算的“消耗战”,进而帮助他们尽可能地远离市场波动,专注地投入到业务上——于是在老爷子巨大的“财富效应”照耀下,每个风险投资人都开始习惯性地在聊项目的时候,问一句“你们的护城河”是什么?
移动互联网时代的创业者会说,护城河是他们无敌的“地推铁军”。电商时代的创业者说,护城河是他们极致的“供应链管理”。新消费时代的创业者可能说,护城河是他们敏锐的市场洞察。
而对于人工智能时代的创业者来说,这个问题的最佳答案,大概率将是“数据”。
虽然人们一聊起人工智能创业,就本能地想到“算力”和“电力”,还编出了一句顺口溜叫“人工智能的尽头是算力,算力的尽头是能源”。但归根结底,无论是算力还是电力都是为“最终结果”服务的,而决定人工智能“最终结果”的正是“数据”。硅谷最顶级的AI投资人之一、A16z创始人马克·安德森就在他的个人播客里非常直白地指出,AI时代真正的创业瓶颈并不是“算力”,而是“训练数据”,因为数据不仅是“有限的”,还是有“所有权的”。
他们还统计到了这样一组数据,在2023年4月至2024年4月期间,由于网站严厉打击将其文本、图像和视频用于人工智能训练,所有数据中有5%是无法被创业者们抓取的——如果仅统计“真正有训练价值的数据”,那么这部分无法被抓取的数据占到了整体的25%。
有传闻称,就连人工智能的头部企业OpenAI也备受“数据困扰”,甚至不得不采取了这样的“笨办法”:他们设立了一个名为“人类数据团队”的部门,聘请数千名程序员、医生、律师,让他们亲手撰写问题的答案,以便训练人工智能。
可以说,谁有办法在技术层面有效地解决“数据”问题,谁就真正找到了人工智能创业的金钥匙。也正是在这样的前提下,一支来自深圳的青年创业团队脱颖而出:
据投中网获悉,视频具身数采企业枢途科技(SynaData)于近日正式完成天使+轮融资,距离由东方富海及兼固资本领投的天使轮融资时隔仅仅两个月。本轮由辰韬资本独家投资,深蓝资本担任长期独家财务顾问,融资资金将主要用于SynaData数据管线的进一步提升和工程化、大规模数据集的生产和交付、以及人才团队的持续扩充。
寻找数据集,难在哪里?
正如上文所说,虽然肉眼可见的是近几年来人工智能模型能力越来越强、AI Agent应用领域越来越广泛、具身智能动作越来越复杂,但主流的数据生产方式,却依旧停留在“人类手把手示范”的时代。如今全国各地遍地开花的具身智能训练中心就是一个非常具体的场景——在正式投入使用之前,需要大量工作人员用牵引遥控的方式,帮助机器人在特定的使用场景内不断重复指定动作,以此来积累足够的数据。
而痛点即市场空间。近年来,人工智能领域里也涌现了大量的“数据集供应商”,其中不乏明星公司。比如被Meta以300亿美元估值收购的Scale AI,定位就是人工智能数据标注和标记服务。此外,像Snowflake、Databricks这些传统数据库供应商也在近几年完成了转型,本着“近水楼台先得月”的优势推出了经过清洗、结构化、经过预处理的即用型数据集,进而吃尽了人工智能的增长红利——据最新的报道显示,Databricks已经启动了最新一轮融资,估值达到了1340亿美元(约合人民币9466.3亿元),相较于去年年底的上一轮融资直接翻倍。
但问题在于,目前这些数据供应商们所采取的技术路线,均存在着自身难以解决的难点。
例如Scale AI采用的人机协作采集和标记路线虽然门槛低、起步快,但随着产品应用得更加广泛,再加上抓取的内容需要进行大量的清理、去重和规范化才能使用,这种技术路线对应的成本将几何倍增加,对大型数据集需求的扩展性有着明显的天花板。而Snowflake、Databricks这些专业数据供应商虽然能保证数据质量与合规问题,但数据更新的及时性以及核心数据的完整性都大打折扣。
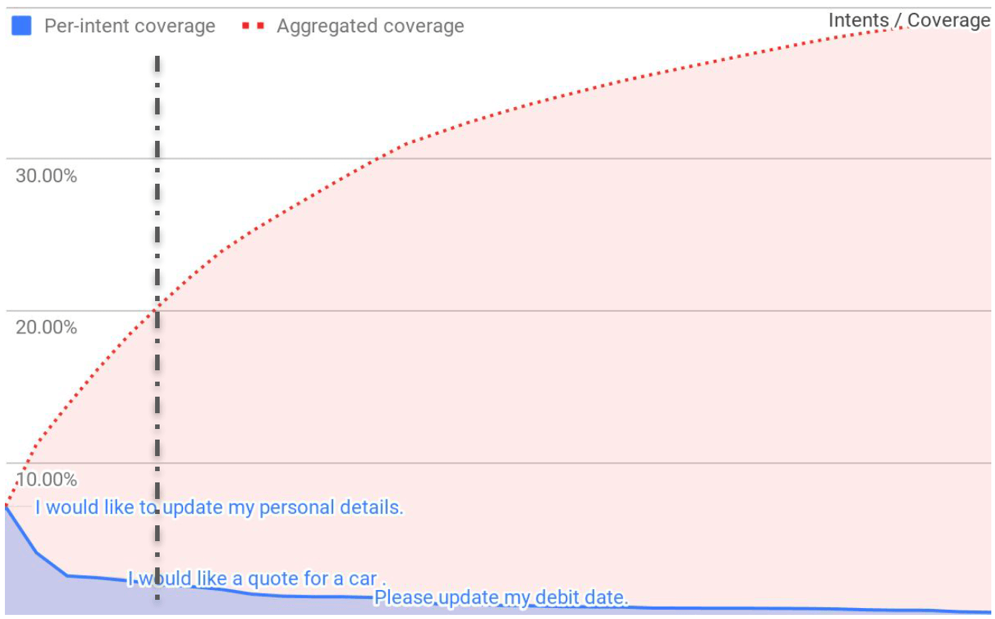
上图来自A16z,研究样本是“AI客服”。A16z分析师指出,在现有的数据采集技术路线下,训练AI客服的时候,最开始的投入还是具备“性价比”的,能够做到“一分耕耘一分收获”——20%的成本投入能覆盖约20%的客户用例。但在跨越20%之后,每多覆盖一个用例,所需的数据收集和清理成本会急剧上升,最终在覆盖40%客户用例的水平上出现停滞,很难出现提升。
再回到上文我们提到的“具身智能训练中心”案例。“人工训练”虽然看起来很“原始”,但对于尚处发展初期的、不得不兼顾成本与发展需要的具身智能企业们来说,并没有太多选择。以至于具身智能的创业者们逐渐进入了另一种困境:
一方面,行业在训练中心上的投入规模越来越大、训练中心的数量越来越多;另一方面由于各本体形态、结构差异巨大,通过自建训练中心采到的数据往往只能用于自家训练,无法跨厂商复用,形成大量“数据孤岛”。
如果用细分领域内最大的数据集进行横向对比,瓶颈更加一目了然:
• 文本:15T Tokens
• 图像:6B Image-Text Pairs
• 视频:2.6B Audio/Visual Features
• 具身智能:仅2.4M Episodes
也就是说,没有规模化、可泛化、可迁移的高质量数据,是人工智能应用目前最大的瓶颈,而具身模型则是人工智能细分赛道中,受到这个瓶颈制约最严重的那一个,也与具身智能今年以来热闹的融资节奏形成了一个非常“刺眼”的反差。
像人类一样,学会“看”
那么枢途科技提出的解决方案是什么呢?
枢途科技成立于2024年,公司成员平均年龄不到28岁,核心研发成员来自于清华大学、上海交通大学、美国佐治亚理工、卡内基梅隆大学、斯坦福大学、香港科技大学等海内外顶尖高校实验室,对具身智能数据采集及处理、具身智能模型架构设计有深入的探索和颠覆式的思考;
他们的共识是,在所有AI技术浪潮里,真正的拐点从来不是“功能变强”,而是“学习方式改变”——从监督学习到自监督学习,从大规模文本到通用多模态语料,正是每一次学习方式的迭代带来了成本结构被改写、能力边界被重新定义。
而人类作为目前已知学习能力最强的生物,人类对于动作、技能的习得并不是依靠别人手把手教会我们每一个动作,而是通过观察大量行为,自然习得动作背后的规律。因此他们认为,如果要真正有效地解决具身智能现在面临的困境,那么就要想办法帮助机器人用更高效的方式理解物理世界的行为和动作;要找到一种媒介将物理世界行为转化为虚拟世界数据,让机器人有能力从这些数据中习得物理世界的常识与行为模式,这个媒介就是“视频数据”。
当然“视频数据”并不是一个全新的技术概念。时间回到今年5月,特斯拉工程主管米兰·科瓦奇(Milan Kovac)通过X平台宣布,Optimus将正式告别传统的动作捕捉和远程操控训练方式,全面转向基于视频数据的“纯视觉”AI训练模式。他强调:“我们的目标之一是让Optimus直接从人类执行任务的互联网视频中学习。这些视频通常是随机摄像头捕捉到的第三人称视角。”
此外,国外的Skild AI提出了利用视频数据解决数据瓶颈的方法;国内的逐际动力、千寻智能、BeingBeyond都提出采用视频数据来提升机器人的智能水平,具身智能产业正在迅速达成一个共识,即传统依赖遥操作和动捕技术的数据采集路径,因其高成本和难以规模化的特性,已成为制约具身智能发展的关键瓶颈。
枢途的差异化在于,他们构建了一套名为SynaData的自动化数据管线,将海量真实世界视频转化为适用于具身智能的通用训练数据,让模型能够从中提取动作逻辑、空间模式和行为线索——并最终迁移到不同的机器人形态与任务场景中。
技术上,从普通的人-物交互2D视频中提取模型训练所需的“具身数据”,最重要的一步是对视频进行高精度的升维重建,SynaData通过结合海量先验知识库与多模态融合算法,将视频中缺失的深度信息、空间结构与物体形态精准还原,提取高精度的人体骨架三维连续动作序列、物体平移旋转轨迹、物体mesh等关键数据模态,并将收集到的人物交互数据以通用的标准化形式存储,成为能够赋能全行业不同玩家的Raw Data。
重建精度是决定数据价值的绝对核心:当机器人执行交互动作时,操作误差往往决定了任务成败。SynaData已将视频重建误差从传统方法普遍存在的±5cm降低至±5mm,实现了数量级的精度突破。毫米级的重建能力,使得视频数据真正具备了“可被机器人直接学习”的质量标准,也让数据从“不可控样本”变成“可扩展生产要素”,推动行业进入数据自主生成和复用的新阶段。
视频数据在被升维后,仍需解决“能否迁移到不同本体上训练”的关键问题。具身智能领域长期存在的挑战,是缺乏一种可靠的跨域Retargeting能力,能够把“人类动作点”与“机械臂/人形机器人结构”进行逐点映射,使其在动力学差异和结构差异下仍能稳定执行动作。
SynaData通过动态结构适配算法,将human-to-humanoid的模仿学习误差降低超过50%,任务成功率提升40%。这一能力让不同机器人可以共享同一数据源,也让“数据跨本体复用”成为现实,从根本上打破了数据孤岛。
在实际验证中,枢途SynaData已经跑通RDT、π0.5、智元Go-1、Diffusion Policy、ACT等主流开源VLA具身模型,是业内唯一完成多家第三方模型端到端验证的数据公司,并已在多家头部具身独角兽公司完成数据验证,商业化闭环全面跑通。
更具想象空间的是,SynaData的数据管线不仅能够提取标准几何与轨迹信息,更能利用现实世界中更丰富的模态,将模型从“模态不足”的限制中解放出来,使下一代具身模型能够成长出更丰富、更强大的抽象与理解能力。
枢途也正是基于这样的能力,自成立以后很快就得到了资本市场以及产业方的广泛关注:
2024年12月,枢途科技拿到了自成立以来的第一笔融资,投资方为奇绩创坛创始人陆奇博士;
2025年8月,英伟达在其官方公众号“NVIDIA英伟达中国”中,将SynaData视为“NVIDIA全栈技术加速枢途科技构建具身训练数据新范式”,认为其实现了2D视频到3D数据的高速重建,以及3D数据至具身多模态训练数据的高速提取,并将所提取的具身多模态训练数据与 Isaac Sim平台进行了融合,实现了从视频3D重建、轨迹等多模态数据提取、仿真环境融合、VLA模型训练的全栈批量化视频数据具身模型训练闭环;
2025年9月,枢途科技获得了2025高通创投-红杉中国创业大赛冠军。随后,枢途科技公布了规模为数千万元人民币的天使轮融资,由东方富海及兼固资本联合领投。
从“资源”变为“基础设施”
从杨立昆、李飞飞们近段时间大谈的“世界模型”,再到特斯拉、枢途科技发力的“视频数据”,我们可以看到在人工智能的发展曲线上,数据不再只是支撑模型的辅助资源,而逐渐成为能否规模化、能否落地、能否持续进化的关键基建。
尤其是对于具身智能而言,作为人工智能最具象化的承载,也是人类下一阶段无可争议的发展方向,其对数据的要求远高于其他模态:场景更复杂、交互更多样、动作更连续、物理规律更细腻。因此,谁能率先建立可扩展的数据体系,谁就掌握了行业的供给侧入口。
这些前提决定了枢途科技的涌现是一个开始:2025年势如潮水的创业潮、融资潮代表的更多是“未来增长的共识”,而并非“产业发展程度”的肯定——人工智能以及具身智能想要成为一个完整的、正向循环的、有通畅产品开发路线的产业,就需要不依赖单一本体、不受限于单一场景,站在产业链上游的大量“基础设施”建设者们。

























